
在这篇博客文章中,我们介绍了一种全新的LlamaIndex数据结构:文档摘要索引。我们描述了与传统的语义搜索相比,它如何有助于提供更好的检索性能,并举例说明。
出身背景
大型语言模型(LLM)的核心用例之一是对自己的数据进行问答。为此,我们将LLM与“检索”模型配对,该模型可以在知识语料库上执行信息检索,并使用LLM对检索到的文本执行响应合成。这个整体框架被称为检索增强生成。
如今,大多数构建LLM支持的QA系统的用户倾向于执行以下某种形式的操作:
- 获取源文档,将每个文档拆分为文本块
- 将文本块存储在矢量数据库中
- 在查询期间,通过嵌入相似性和/或关键字过滤器来检索文本块。
- 执行响应合成
由于各种原因,这种方法提供的检索性能有限。
现有方法的局限性
- 使用文本块嵌入检索有一些局限性。
- 文本块缺少全局上下文。通常,这个问题需要特定区块中索引之外的上下文。
- 仔细调整top-k/相似性得分阈值。如果值太小,就会错过上下文。让价值变得太大,成本/延迟可能会随着不相关的上下文而增加。
嵌入并不总是为问题选择最相关的上下文。嵌入本质上是在文本和上下文之间分别确定的。
添加关键字过滤器是增强检索结果的一种方法。但这也带来了一系列挑战。我们需要手动或通过NLP关键字提取/主题标记模型为每个文档充分确定适当的关键字。此外,我们还需要从查询中充分推断出正确的关键字。
文档摘要索引
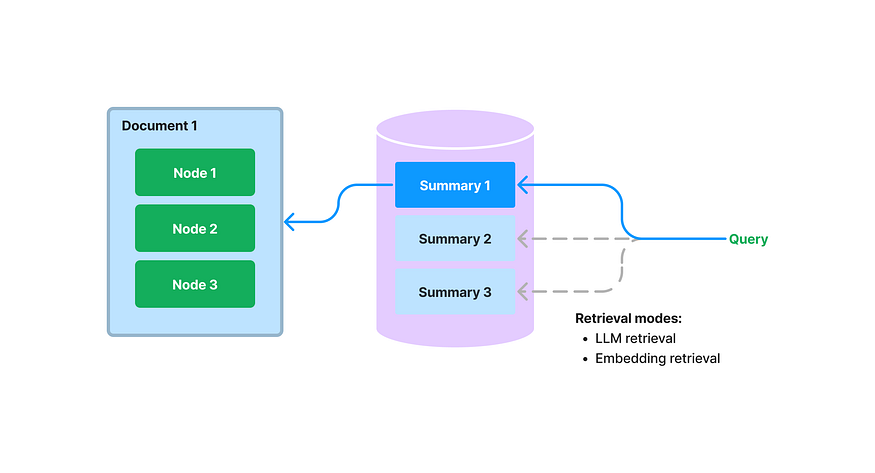
A diagram for the Document Summary Index
我们在LlamaIndex中提出了一个新的索引,该索引将为每个文档提取/索引非结构化文本摘要。该索引可以帮助提高现有检索方法之外的检索性能。它有助于索引比单个文本块更多的信息,并且比关键字标签具有更多的语义。它还允许更灵活的检索形式:我们可以进行LLM检索和基于嵌入的检索。
工作原理
在构建期间,我们摄取每个文档,并使用LLM从每个文档中提取摘要。我们还将文档拆分为文本块(节点)。摘要和节点都存储在我们的文档存储抽象中。我们维护从摘要到源文档/节点的映射。
在查询期间,我们使用以下方法,根据相关文档的摘要将其检索到查询中:
- 基于LLM的检索:我们向LLM提供一组文档摘要,并要求LLM确定哪些文档是相关的+它们的相关性分数。
- 基于嵌入的检索:我们基于摘要嵌入相似性(具有top-k截断)来检索相关文档。
注意,这种对文档摘要的检索方法(即使是基于嵌入的方法)与对文本块的基于嵌入的检索不同。文档摘要索引的检索类检索任何选定文档的所有节点,而不是在节点级别返回相关块。
存储文档的摘要还可以实现基于LLM的检索。我们可以先让LLM检查简明的文档摘要,看看它是否与查询相关,而不是一开始就将整个文档提供给LLM。这利用了LLM的推理能力,后者比基于嵌入的查找更先进,但避免了将整个文档馈送到LLM的成本/延迟
其他见解
带摘要的文档检索可以被认为是所有文档中语义搜索和强力摘要之间的“中间地带”。我们根据与给定查询的摘要相关性来查找文档,然后返回与检索到的文档对应的所有*节点*。
我们为什么要这样做?这种检索方法通过在文档级别检索上下文,在文本块上为用户提供了比top-k更多的上下文。但是,这也是一种比主题建模更灵活/更自动化的方法;不用再担心你的文本是否有正确的关键词标签了!
实例
让我们通过一个例子来展示文档摘要索引,以及维基百科关于不同城市的文章。
本指南的其余部分展示了相关的代码片段。你可以在这里找到完整的演练(这里是笔记本链接)。
我们可以在一组文档上构建GPTDocumentSummaryIndex,并传入ResponseSynthesizer对象来合成文档的摘要。
from llama_index import (
SimpleDirectoryReader,
LLMPredictor,
ServiceContext,
ResponseSynthesizer
)
from llama_index.indices.document_summary import GPTDocumentSummaryIndex
from langchain.chat_models import ChatOpenAI
# load docs, define service context
...
# build the index
response_synthesizer = ResponseSynthesizer.from_args(response_mode="tree_summarize", use_async=True)
doc_summary_index = GPTDocumentSummaryIndex.from_documents(
city_docs,
service_context=service_context,
response_synthesizer=response_synthesizer
)
一旦建立了索引,我们就可以获得任何给定文档的摘要:
summary = doc_summary_index.get_document_summary("Boston")
接下来,让我们浏览一个基于LLM的索引检索示例。
from llama_index.indices.document_summary import DocumentSummaryIndexRetriever
retriever = DocumentSummaryIndexRetriever(
doc_summary_index,
# choice_select_prompt=choice_select_prompt,
# choice_batch_size=choice_batch_size,
# format_node_batch_fn=format_node_batch_fn,
# parse_choice_select_answer_fn=parse_choice_select_answer_fn,
# service_context=service_context
)
retrieved_nodes = retriever.retrieve("What are the sports teams in Toronto?")
print(retrieved_nodes[0].score)
print(retrieved_nodes[0].node.get_text())The retriever will retrieve a set of relevant nodes for a given index.
请注意,LLM除了返回文档文本之外,还返回相关性分数:
8.0 Toronto ( (listen) tə-RON-toh; locally [təˈɹɒɾ̃ə] or [ˈtɹɒɾ̃ə]) is the capital city of the Canadian province of Ontario. With a recorded population of 2,794,356 in 2021, it is the most populous city in Canada...
我们还可以使用索引作为整体查询引擎的一部分,不仅可以检索相关上下文,还可以合成对给定问题的响应。我们可以通过高级API和低级API实现这一点。
高级API
query_engine = doc_summary_index.as_query_engine(
response_mode="tree_summarize", use_async=True
)
response = query_engine.query("What are the sports teams in Toronto?")
print(response)
Lower-level API
# use retriever as part of a query engine
from llama_index.query_engine import RetrieverQueryEngine
# configure response synthesizer
response_synthesizer = ResponseSynthesizer.from_args()
# assemble query engine
query_engine = RetrieverQueryEngine(
retriever=retriever,
response_synthesizer=response_synthesizer,
)
# query
response = query_engine.query("What are the sports teams in Toronto?")
print(response)
接下来的步骤
对任何文本进行自动汇总的方法都非常令人兴奋。我们很高兴能够在两个领域进行扩展:
继续探索不同层次的自动汇总。目前它是在文档级别,但把一个大的文本块汇总成一个小的文本块呢?(例如一个衬垫)。
继续探索基于LLM的检索,摘要有助于解锁它。
此外,我们将分享下面的示例指南/笔记本,以防您错过上面的内容:
- 登录 发表评论