category
如果你一直在关注深度学习的最新消息,你就会意识到深度学习中的数据和模型非常庞大。数据集的大小可能达到PB级,模型本身的大小也可能达到数百GB。这意味着,即使是模型本身也无法放入标准GPU芯片的内存中。高效和智能的并行化以及可恢复性在深度学习领域至关重要。
最近的一些文献主要关注LLM系统的基础设施配置。如果你了解VAST,你就会知道这正是我们的专长,因为我们不仅喜欢谈论数据基础设施,还喜欢谈论所有可以推动技术从数据中获得最大价值的神奇方法。因此,事不宜迟,我们想向您介绍并行性如何影响当今最复杂模型中的检查点和恢复操作。
在所有维度上并行化
对于LLM和其他大规模深度学习算法中固有的大型数据集和大型模型,数据和模型本身都太大,无法放入内存。例如,具有数十亿个参数的典型LLM将不适合内存。GPT-3的大小大于500 GB,典型的GPU限制为80 GB的VMEM。此外,单个A100 GPU需要几百年的时间来训练GPT-3(实际上需要300多年)。因此,多维并行性对于训练和微调模型至关重要。
这一论点基于该领域的广泛研究,特别是斯坦福大学、英伟达和微软研究院的开创性论文《威震天LM大规模训练》。作者提出,并在现场得到证实,三种并行性的综合允许LLM中更易于管理和恢复的工作负载:
- 数据并行性:整个模型在多个GPU或CPU上复制,并在它们之间分配训练数据。这是最简单、最常见的并行类型,但对于大型模型来说,它通常是内存密集型的。
- 模型并行性:模型本身被分为离散层或张量,然后分布在多个GPU或CPU上。这可能很难实现,但比数据并行更节省内存。
- 流水线并行性:模型训练过程被分成更小的步骤,并在不同的GPU或CPU上执行。这可能会增加延迟或有效地序列化模型,但如果做得好,可以提高训练吞吐量。
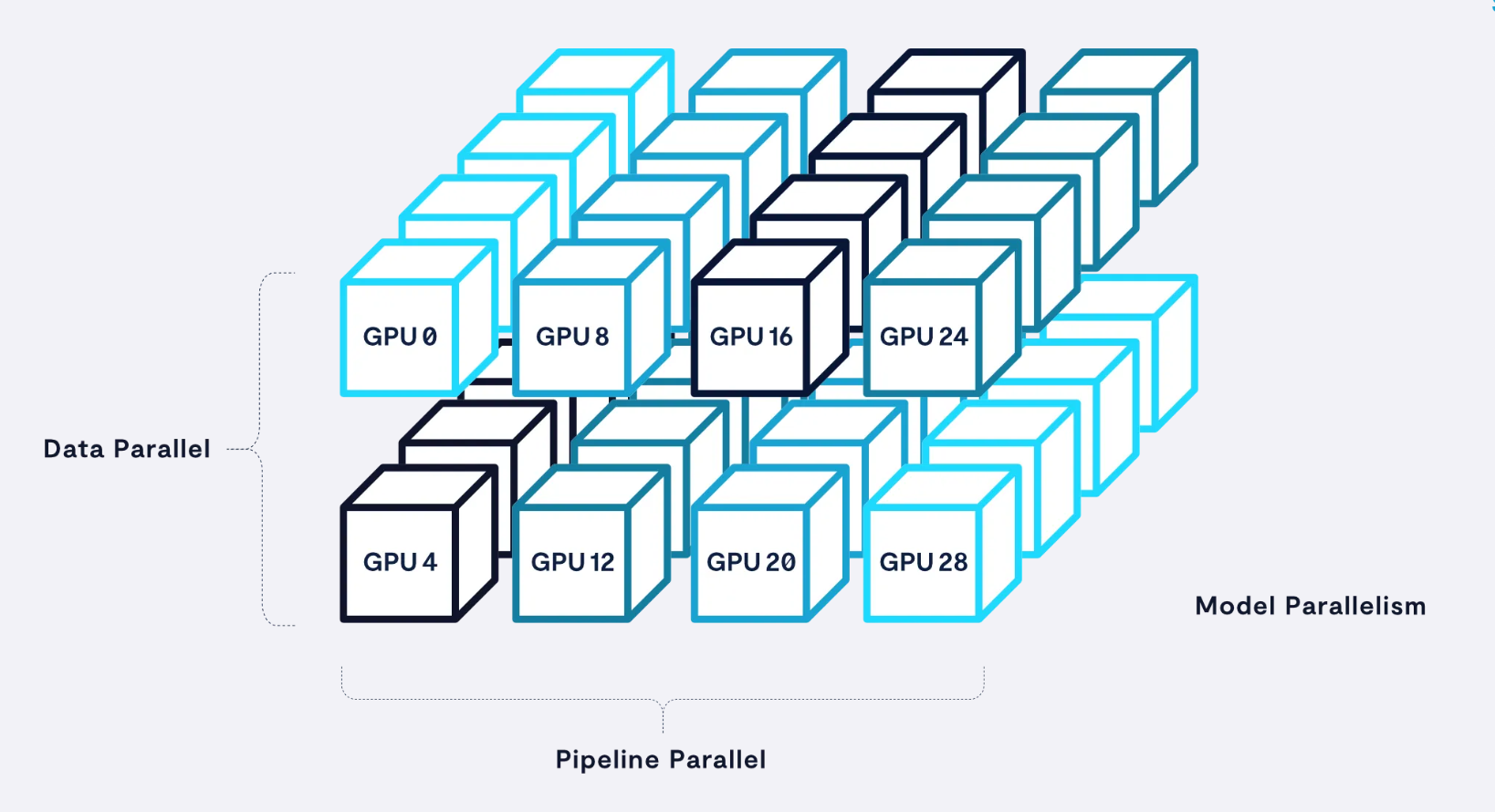
通过结合三种主要类型的并行性,整体模型训练性能可以提高几个数量级。
检查点和可恢复性
一旦模型被并行化,它仍然可能需要一个月或更长时间才能完全运行一个训练作业。因此,该模型执行的可恢复性成为一个关键考虑因素,应该对系统的状态进行定期检查。通常,检查点是在每个训练周期之后完成的(即,对训练数据集进行一次完整的遍历)。对于大多数LLM,每个令牌在训练过程中只会看到一次——因此训练大约在1个历元内发生——因此检查点是在一定数量的训练步骤后完成的。然后,例如,如果模型在训练过程中中途失败,与其失去进度,不如恢复到检查点。
或者,有时有必要在模型进展的中途返回并更改参数。检查点将允许这种更改,而不需要从一开始就运行完整的模型。此外,检查点对于模型的可重复性至关重要;随着大规模模型继续成为主流,能够重新运行模型训练以显示合规性或可靠地再现结果无疑将变得更加重要。
因此,确保人工智能架构的设计能够充分考虑检查点操作是非常重要的。请注意,AI模型本身通常不受I/O限制,它们仍然受GPU限制。然而,检查点过程是写密集型的,恢复过程甚至是读密集型的。实际上,AI架构的I/O要求与检查点和恢复操作直接相关。
检查点大小:让我们谈谈数字
近年来,随着以人工智能为重点的技术向公众发布,基础设施的规模一直是人们经常谈论的话题。因此,GPT-3是讨论如何为深度学习(尤其是LLM)充分提供基础设施的完美例子。让我们通过这个例子,计算一下如何调整这样一个系统的大小:
- GPT-3有1750亿个参数,让我们假设我们将在部署此LLM时使用上述所有三种类型的并行性,并且我们将在1024个GPU上部署它,这相当于128台NVIDIA DGX-A100机器(每台机器包含8个GPU)。
- 如上所述,~500 GB的模型本身太大,无法容纳单个GPU的80 GB内存,因此我们将使用基于张量的模型并行性将模型分布在DGX节点中的8个GPU上。
- 为了实现流水线并行性,我们将在8个DGX或八位字节的组中复制模型。请注意,这里描述的Pipeline Parallel八位字节是自包含的,包括LLM的整个模型和管道,因此每个系统只需要检查一个八位字节,而不管集群的整体大小如何,因为它是系统的完整表示。
- 因此,每个GPU被配置为1个线程,每个8-GPU DGX 8个线程,每8-DGX八位字节64个线程。这导致缓冲顺序大块写入操作,每个线程写入1个检查点文件。
- 注意:这通常是一个混淆点,因为一个常见的错误假设是集群中的每个GPU都需要被检查点。并非如此——如图所示,在这个示例系统中有一个检查点八位字节。
- 最后,我们将数据并行化为16组8个流水线并行系统(128个节点)。
张量模型、流水线和数据并行性的结合允许威震天模式中的线性尺度达到1万亿参数大小的模型,触发器效率接近理论值的50%。
这个例子的底线是,检查点的大小根本不取决于数据的大小或GPU的数量,而只取决于模型的大小。在为LLM配置基础设施时,关于检查点的唯一考虑因素是了解您将要部署的模型的大小,然后确保有足够的带宽来写入检查点和读取作为I/O边界的检查点。
更深入地研究检查点数学
当你像我们一样是一个秘密的学术书呆子时(说真的,我们都有物理学博士学位),深入了解如何检查和恢复LLM培训系统背后的科学是很有趣的,当然,我们想为讨论带来一些数据。下表显示了三种流行LLM的模型大小和检查点状态大小之间的线性相关性:
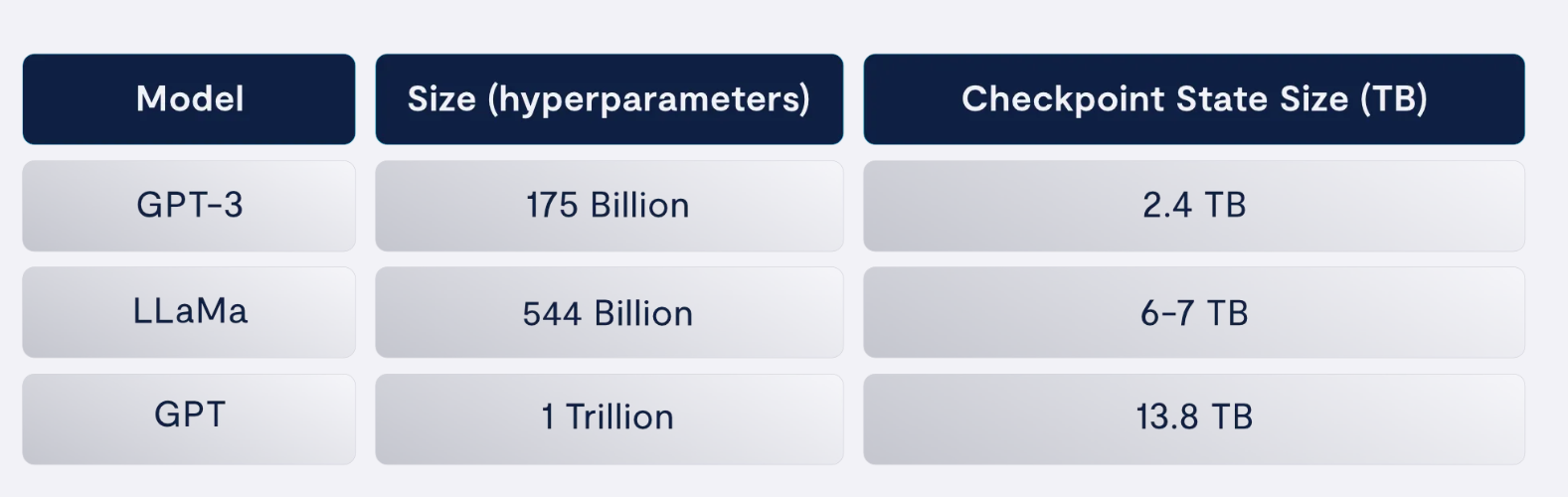
注:GPT是一类模型,上面的数字来自上面引用的学术论文。
显然,检查点大小与模型大小直接相关,事实证明,最终的需求是一个简单的计算。此检查点状态大小仅取决于模型大小,而不取决于数据集的大小、检查点频率或要训练的GPU数量。
检查点操作的详细要求和时间安排
让我们回到上面引用的论文,它显示了一个使用3072个GPU(384个DGX)进行1万亿参数训练的示例:

当读取检查点以将系统恢复到先前状态时,系统会受到速率限制,因为存储并行文件系统只能提供1TB/s的读取带宽。然而,检查点13.8 TB的写入性能为273 GB/s;写入过程只能达到存储子系统可用写入带宽的40%。这是有限的,因为每个DGX系统只使用8个线程,因此每个DGX只能提供约8 GB/s的速度。顺便说一句,这是我们在获得NVIDIA SuperPOD认证时所经历的测试之一——缓冲写入与线程数。对本地NVMe突发缓冲区的测量也会产生这个结果。
在配置基础设施时,系统编写检查点需要多长时间是一个关键考虑因素。在这个继续的例子中,参与检查点写入过程的512个GPU所需的带宽为0.53 GB/s/GPU或大约4.3 GB/s/DGX,即使是本文研究的最大型号也是如此。这导致GPT-3的检查点时间为50秒,这是完全合理的。NVIDIA建议每4小时进行一次检查点操作——由于检查点操作,这将造成0.3%的开销。NVIDIA的指导是,此开销应小于5%左右,因此即使是较低的写入带宽也足以在这个容差范围内。
运行还原操作需要多长时间?
恢复所需的读取带宽将是数据并行度(本例中为6)乘以写入,因此6x273 GB/s=1.638 TB/s。写入带宽是恢复所需读取带宽的17%。只要存储子系统可以提供1.64 TB/s的读取速度和280 GB/s的写入速度,检查点时间将是最佳的——对于13.8 TB的模型状态,大约为50秒。对于将大型模型恢复到之前的稳定状态来说,这是一个完全合理的时间,甚至可能有些过头了。
检查站上的检查站
我们最近看到市场上的讨论表明,系统需要集群中所有GPU的每个GPU 1 GB/s作为检查点。正如现在所希望的那样,这不是基于现实的计算。正如我们上面所示,虽然每个检查点可能需要~1GB/s/GPU,但参与训练的每个GPU都不需要这样做,只有流水线并行集中的GPU才需要这样做。以万亿参数模型为例,273 GB/s的写入带宽实际上相当于每个GPU仅0.53 GB/s(因为有512个GPU并行运行,或64个8-GPU服务器)。因此,并非每个GPU都需要同时检查点或需要全写带宽;这避免了为此类训练集群过度配置存储硬件。
请记住,检查点不需要绝对反映系统中的所有内容;它只需要是系统状态的连贯记录,您可以从中恢复该系统。换句话说,您需要以一致的状态拍摄模型和管道的快照。重要的是要认识到,这并不取决于数据,只取决于模型当前状态中存在的权重和偏差,换句话说,取决于模型本身的大小。
结论:数学和科学很酷
最后,我们给你的建议是:在构建人工智能系统时,一定要依靠数学和科学来驱动考虑因素。考虑到我们在这里谈论的规模和尺度,小错误可能会付出难以置信的代价。一定要依靠真正的技术知识和计算,而不是纸上谈兵的数学或别有用心的有偏见的指导方针。
有兴趣了解更多或进一步讨论这个问题吗?我们很乐意收到您的来信!联系我们,我们很乐意帮助您构建合适大小的人工智能系统,帮助您扩展业务及其数据。
- 登录 发表评论