

在人工智能领域,自然语言处理(NLP)被广泛认为是阅读、破译、理解和理解人类语言的最重要工具。有了NLP,机器可以令人印象深刻地模仿人类的智力和能力,从文本预测到情感分析再到语音识别。
什么是自然语言处理?
语言模型在NLP应用程序的开发中起着至关重要的作用。然而,从头开始构建复杂的NLP语言模型是非常耗时的。出于这个原因,人工智能和机器学习的研究人员和开发人员对预先训练的语言模型深信不疑。迁移学习是一种用于训练模型的技术,该模型使用在另一个数据集上训练的数据集来执行任务。然后使用一个新的数据集来重新调整模型的用途,以执行不同的NLP功能。
经过预训练的模型:为什么它们有用?
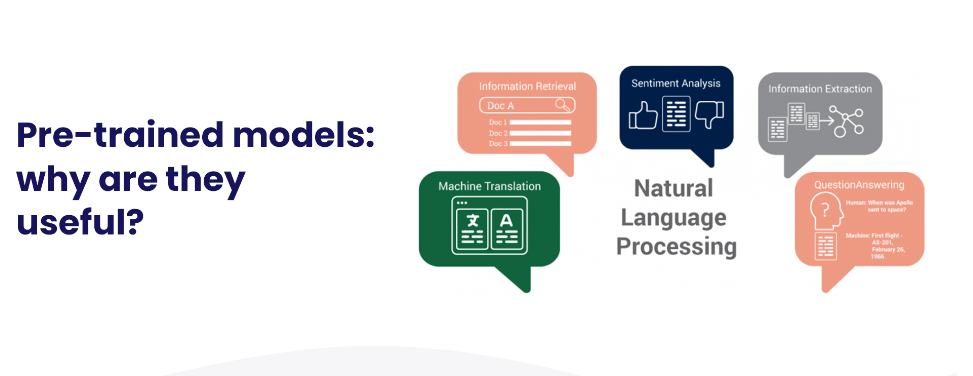
然后,我们可以使用预训练的模型来解决我们自己的NLP问题,而不是从头开始构建模型。
预先训练的模型是为解决特定问题而设计的,需要进行一些微调,因此与编写新的语言模型相比,它们节省了大量时间和计算资源。
NLP语言模型根据其功能有几个预先训练的类别。
1. BERT (Bidirectional Encoder Representations from Transformers)
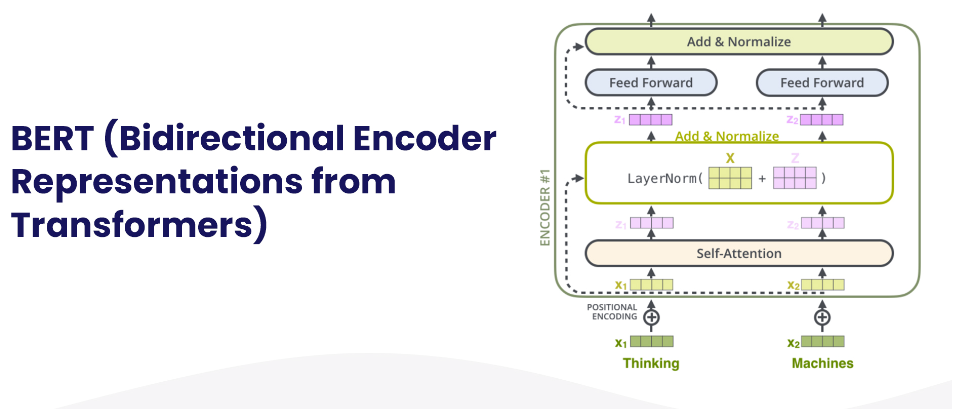
BERT是谷歌开发的一种用于NLP预训练的技术。对于语言理解,它依赖于一种新的神经网络架构,称为Transformer。该技术是为了解决神经机器翻译或序列转导的问题而开发的。因此,它非常适合于将输入序列转换为输出序列的任何任务,例如语音识别、文本到语音的转换等。
最初,转换器包含两种机制:一个是读取文本输入的编码器,另一个是创建预测的解码器。通过BERT,可以创建语言模型。到目前为止,只使用了编码器机制。
使用BERT算法可以有效地执行11个NLP任务。一个由BookCorpus的8亿个单词和维基百科的25亿个单词组成的数据集被用于训练。BERT的效率体现在谷歌搜索上,这是最好的例子之一。BERT用于其他谷歌应用程序中的文本预测,如谷歌文档和Gmail智能合成。
2. RoBERTa (Robustly Optimized BERT Pre-training Approach)
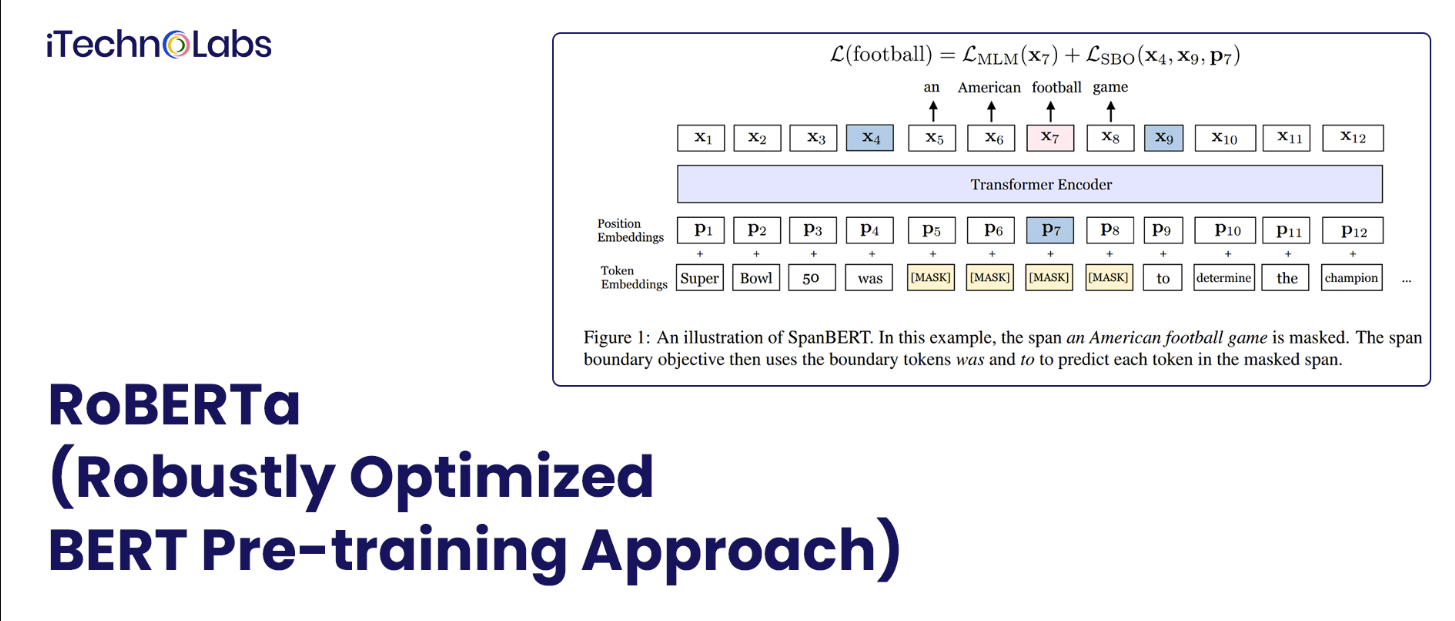
RoBERTa方法是一种预训练自监督自然语言处理算法的优化方法。通过学习和预测有意隐藏的文本部分,该系统基于BERT的语言掩蔽策略建立了语言模型。
在RoBERTa中,参数会被修改。例如,在训练时使用更大的小批量,下一句不再是BERT中的预训练目标,等等。RoBERTa等预训练模型擅长一般语言理解评估(GLUE)基准的所有任务,非常适合NLP训练任务,如识别问题、分析对话和分类文档。
3.OpenAI的GPT-3
使用GPT-3,您可以进行翻译、回答问题、创作诗歌、完成完形填空任务,以及即时解读单词。由于其最近的进步,GPT-3还用于生成代码和撰写新闻文章。
GT-3可以管理不同单词之间的统计信息。该模型中有超过1750亿个参数,这些参数是从45 TB的文本中学习的。因此,它是目前最大的预训练自然语言处理模型之一。
GPT-3的好处是可以在不需要微调的情况下处理下游任务。该模型可以使用“文本输入,文本输出”API重新编程,该API允许开发人员编写指令。
4. ALBERT
随着预先训练的语言模型变得越来越大,下游任务变得更加准确。然而,模型大小的增加导致训练时间变慢,以及GPU/TPU内存限制。谷歌开发了一个轻量级的BERT(来自变压器的双向编码器表示)来解决这个问题。使用了两种技术来减少其参数:
参数化嵌入:这里,隐藏层和词汇嵌入是分别测量的。
跨层共享参数:这可以防止参数数量随着网络的增长而增加。
通过使用这些技术,降低了内存消耗,提高了模型的训练速度。由于ALBERT在句子顺序预测方面的自我监督损失,这种损失是关于句子间连贯性的BERT限制。
5.XLNet
使用去噪自动编码的语言模型,如BERT,比使用自回归方法的模型性能更好。这就是为什么有XLNet的原因,它使用自回归预训练。它允许学生学习双向上下文,并使用自回归预训练克服了BERT的局限性。许多任务,包括自然语言推理、文档排名、情感分析、问答等,都被认为优于XLNet的BERT。
6. OpenAI’s GPT2
除了在特定任务数据集上使用监督学习来完成诸如问答、机器翻译、阅读理解和摘要之类的任务外,其他自然语言处理任务通常也使用监督学习。在OpenAI的GPT2中,在一个名为WebText的数百万网页的新数据集上训练,即使没有明确的监督,语言模型也开始学习这些任务。该模型处理了各种各样的任务,并在各种各样的工作中产生了有希望的结果。
7.StructBERT
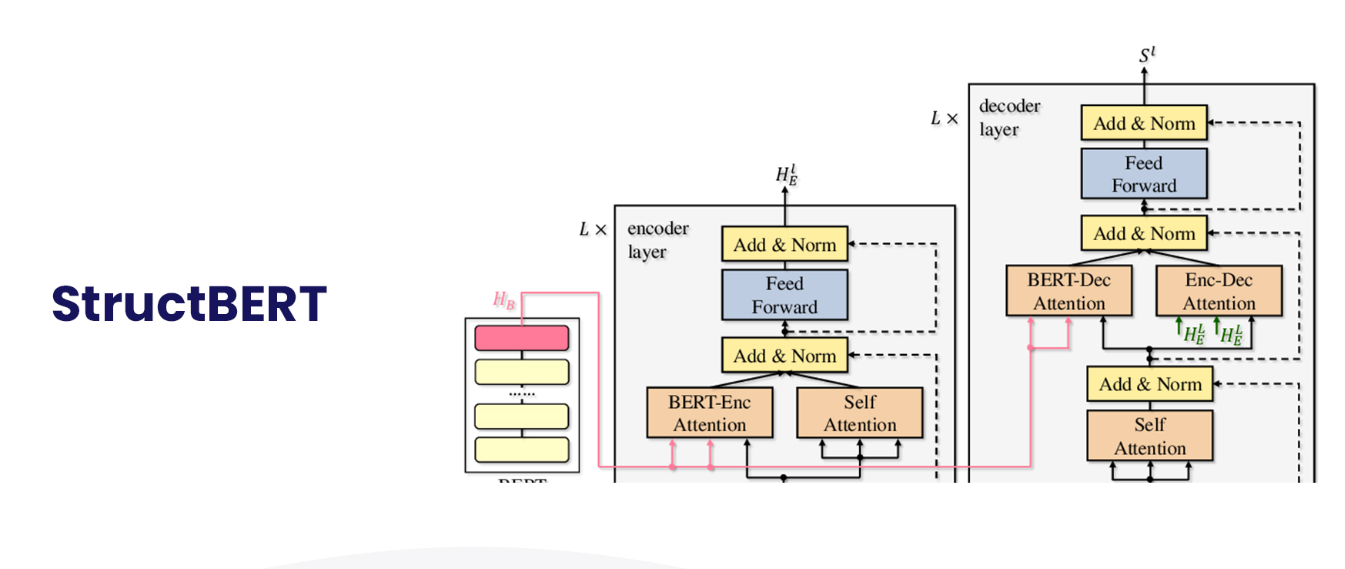
预训练的语言模型,如BERT(及其稳健优化版本RoBERTa),在自然语言理解(NLU)中获得了大量关注,在一系列NLU任务中实现了无与伦比的准确性,如自然语言推理、情感分类、问答和语义文本相似性。通过将语言结构纳入预训练,StructBERT将BERT扩展到一个基于Elman线性化探索工作的新模型。通过结构预训练,StructBERT系统在GLUE基准测试中产生了令人惊讶的结果(优于所有已发表的模型),SQUAD v1.1 F1得分为93.0,SNLI准确率为91.7。除了回答问题、情绪分析、文档摘要外,StructBERT还可以帮助完成各种NLP任务。
8. T5 (Text-to-Text Transfer Transformer)
它已经成为自然语言处理(NLP)中一种强大的技术,可以先在数据丰富的任务上训练模型,然后为下游任务进行微调。迁移学习的有效性导致了方法、方法和实践的多样性。为了在NLP中为迁移学习设定一个新的标准,谷歌提出了一种统一的方法。因此,他们建议将NLP问题视为文本对文本问题。这样的框架允许不同的任务——摘要、情绪分析、问答和机器翻译——使用相同的模型、目标、训练过程和解码过程。一个名为Text to Text Transfer Transformer(T5)的模型使用网络抓取数据进行训练,以在许多NLP任务中得出最先进的结果。
9. ELECTRA (Efficiently Learning an Encoder that Classifies Token Replacements Accurately)
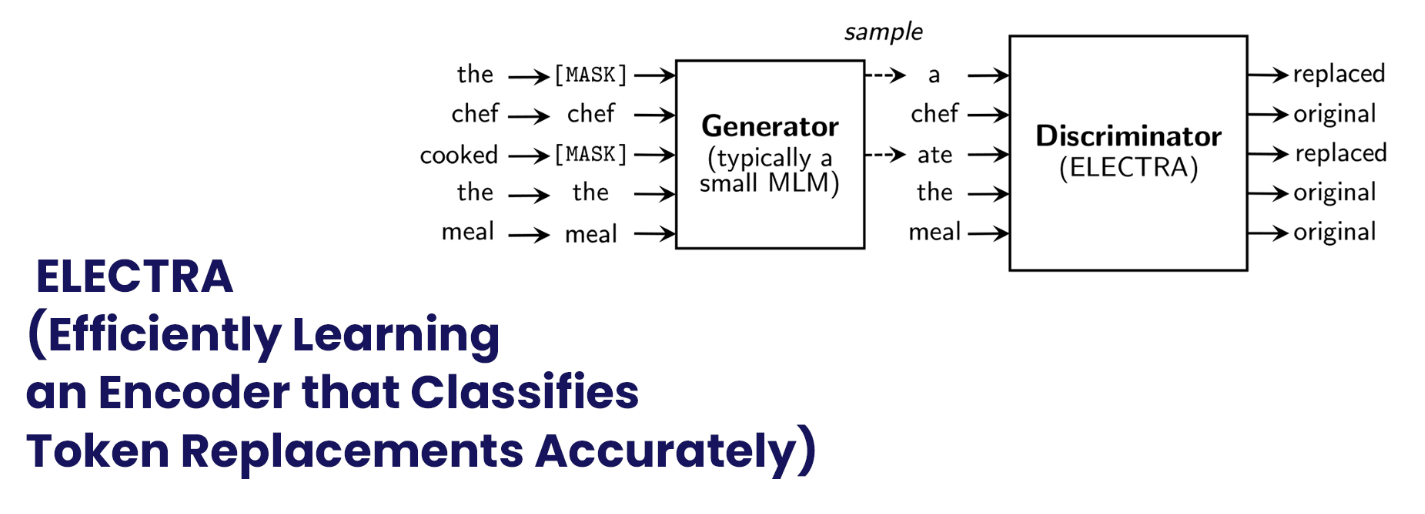
掩蔽语言建模(MLM)预训练方法使用掩蔽来替换输入中的一些令牌,然后训练模型以恢复令牌的原始含义。当应用于下游NLP任务时,它们往往会产生良好的结果,但通常需要大量的计算能力。专家们提出了一种称为替代令牌检测的替代方案,它更具样本效率。他们的方法用来自小型发电机网络的合理替代品取代了一些代币,而不是屏蔽输入。然后,专家们训练一个判别模型,以识别损坏输入中的每个令牌是否被生成器样本替换,而不是训练一个预测损坏令牌的原始身份的模型。
可以用T5中的所有输入令牌来替换屏蔽掉的输入令牌子集。生成替换令牌的生成器以最大似然进行训练,使其不具有对抗性,尽管与GAN相似。ELECTRA在计算上是高效的。
10. DeBERTa (Decoding-enhanced BERT with disentangled attention)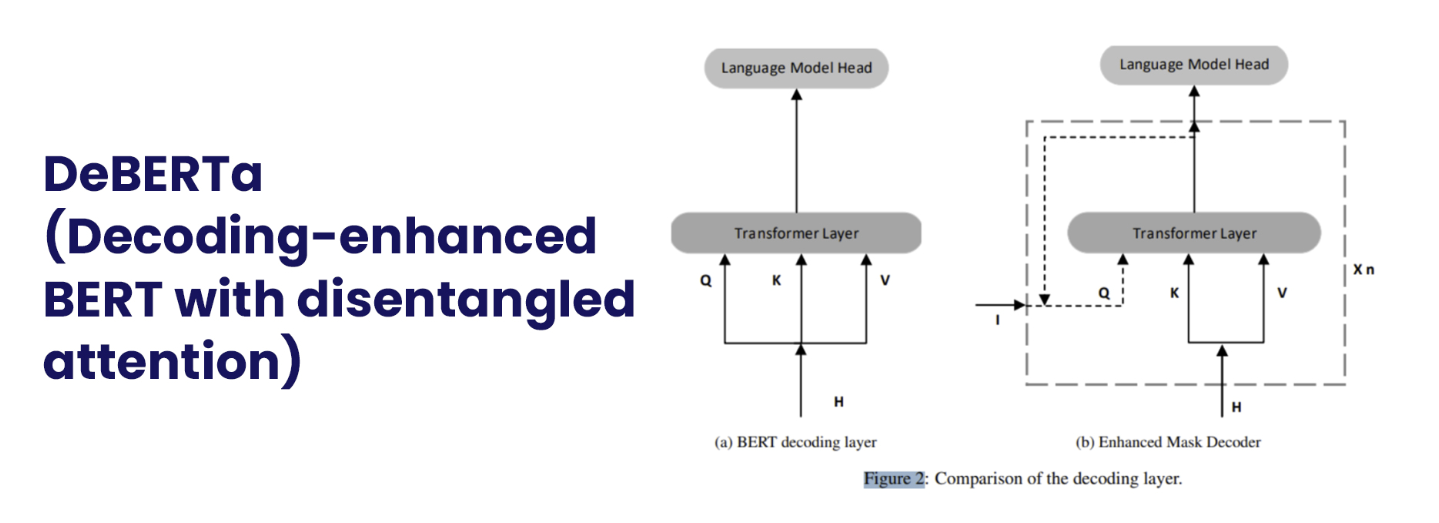
DeBERTa比BERT有两个主要改进,即增强的掩码解码系统和消除纠缠的注意力。通过对令牌/单词的内容和相对位置进行编码,DeBERTa将它们表示为两个向量。虽然DeBERTa的自我关注机制沿着内容到内容、内容到位置和位置到内容的路线运行,但BERT的自我关注仅由前两个元素组成。为了对令牌序列中的相对位置进行全面建模,作者提出还需要位置到内容的自我关注。此外,DeBERTa具有增强的掩码解码器,它为解码器提供了令牌/字的绝对和相对位置。在SuperGLUE基准测试中,DeBERTa的放大变体首次实现了比人类更好的性能。截至撰写本文时,德贝塔合奏团在SuperGLUE排名第一。
很明显,经过预训练的nlp语言模型有很多优点。这些模型对开发人员来说是一个很好的资源,因为它们可以帮助他们实现精确的输出,节省资源,并在人工智能应用程序开发上花费时间。
你如何选择对你的人工智能项目最有效的NLP语言模型?这取决于几个因素,包括项目的规模、数据集的类型和使用的培训方法。如果您想了解哪种NLP语言模型将帮助您实现最大准确性并缩短项目上市时间,请联系我们的人工智能专家。
这可以通过与他们建立免费咨询会议来实现,在此期间,他们可以指导您开发基于人工智能的应用程序的正确方法。
- 登录 发表评论