category
Ray正在人工智能工程领域崭露头角,对扩展LLM和RL至关重要
Spark在数据工程中几乎是必不可少的。Ray正在人工智能工程领域崭露头角。
雷是伦敦大学学院Spark的继任者。Spark和Ray有很多相似之处,例如用于计算的统一引擎。但Spark主要专注于大规模数据分析,而Ray则是为机器学习应用程序设计的。
在这里,我将介绍Ray,并介绍如何使用Ray扩展大型语言模型(LLM)和强化学习(RL),然后总结Ray的怀旧和趋势。
Ray简介
Ray是一个开源的统一计算框架,可以轻松扩展人工智能和Python的工作负载,从强化学习到深度学习,再到模型调整和服务。
下面是Ray的最新架构。它主要有三个组件:Ray Core、Ray AI Runtime和Storage and Tracking。

Ray 2.x and Ray AI Runtime (AIR) (Source: January 2023 Ray Meetup)
Ray Core为构建和扩展分布式应用程序提供了少量核心原语(即任务、参与者、对象)。
Ray AI Runtime(AIR)是一个可扩展的统一ML应用工具包。AIR能够简单地扩展单个工作负载、端到端工作流和流行的生态系统框架,所有这些都只需使用Python。
AIR建立在Ray一流的预处理、培训、调整、评分、服务和强化学习库的基础上,将集成生态系统整合在一起。
Ray实现了工作负载从笔记本电脑到大型集群的无缝扩展。Ray集群由单个头节点和任意数量的连接辅助节点组成。工作节点的数量可以根据Ray集群配置指定的应用程序需求进行自动缩放。头节点运行自动缩放器。
我们可以提交作业以在Ray集群上执行,也可以通过连接到头部节点并运行Ray.init来交互使用集群。
启动并运行Ray很简单。下面将说明如何安装它。
安装Ray
$ pip install ray ████████████████████████████████████████ 100% Successfully installed ray $ python >>>import ray; ray.init() ... INFO worker.py:1509 -- Started a local Ray instance. View the dashboard at 127.0.0.1:8265 ...
Install Ray libraries
pip install -U "ray[air]" # installs Ray + dependencies for Ray AI Runtime pip install -U "ray[tune]" # installs Ray + dependencies for Ray Tune pip install -U "ray[rllib]" # installs Ray + dependencies for Ray RLlib pip install -U "ray[serve]" # installs Ray + dependencies for Ray Serve
此外,Ray可以在Kubernetes和云虚拟机上大规模运行。
使用Ray缩放LLM和RL
ChatGPT是一个重要的人工智能里程碑,具有快速增长和前所未有的影响力。它建立在OpenAI的GPT-3大型语言模型家族(LLM)的基础上,采用了Ray。
OpenAI首席技术官兼联合创始人Greg Brockman表示,在OpenAI,我们正在解决世界上一些最复杂、最苛刻的计算问题。Ray为这些最棘手的问题提供了解决方案,并使我们能够比以前更快地大规模迭代。
在SageMaker培训平台的240 ml.p4d.24个大型实例上训练GPT-3大约需要25天。挑战不仅在于处理,还在于记忆。Wu Tao 2.0似乎只需要1000多个GPU来存储其参数。
训练ChatGPT,包括像GPT-3这样的大型语言模型,需要大量的计算资源,估计要花费数千万美元。通过授权ChatGPT,我们可以看到Ray的可扩展性。
Ray试图解决具有挑战性的ML问题。它从一开始就支持培训和服务强化学习模式。
让我们用Python编写代码,看看如何训练大规模的强化学习模型,并使用Ray serve为其提供服务。
步骤1:安装强化学习策略模型的依赖项。
!pip install -qU "ray[rllib,serve]" gym
第二步:定义大规模强化学习策略模型的培训、服务、评估和查询。
import gym
import numpy as np
import requests
# import Ray-related libs
from ray.air.checkpoint import Checkpoint
from ray.air.config import RunConfig
from ray.train.rl.rl_trainer import RLTrainer
from ray.air.config import ScalingConfig
from ray.train.rl.rl_predictor import RLPredictor
from ray.air.result import Result
from ray.serve import PredictorDeployment
from ray import serve
from ray.tune.tuner import Tuner
# train API for RL by specifying num_workers and use_gpu
def train_rl_ppo_online(num_workers: int, use_gpu: bool = False) -> Result:
print("Starting online training")
trainer = RLTrainer(
run_config=RunConfig(stop={"training_iteration": 5}),
scaling_config=ScalingConfig(num_workers=num_workers, use_gpu=use_gpu),
algorithm="PPO",
config={
"env": "CartPole-v1",
"framework": "tf",
},
)
tuner = Tuner(
trainer,
_tuner_kwargs={"checkpoint_at_end": True},
)
result = tuner.fit()[0]
return result
# serve RL model
def serve_rl_model(checkpoint: Checkpoint, name="RLModel") -> str:
""" Serve an RL model and return deployment URI.
This function will start Ray Serve and deploy a model wrapper
that loads the RL checkpoint into an RLPredictor.
"""
serve.run(
PredictorDeployment.options(name=name).bind(
RLPredictor, checkpoint
)
)
return f"http://localhost:8000/"
# evaluate RL policy
def evaluate_served_policy(endpoint_uri: str, num_episodes: int = 3) -> list:
""" Evaluate a served RL policy on a local environment.
This function will create an RL environment and step through it.
To obtain the actions, it will query the deployed RL model.
"""
env = gym.make("CartPole-v1")
rewards = []
for i in range(num_episodes):
obs = env.reset()
reward = 0.0
done = False
while not done:
action = query_action(endpoint_uri, obs)
obs, r, done, _ = env.step(action)
reward += r
rewards.append(reward)
return rewards
# query API on the RL endpoint
def query_action(endpoint_uri: str, obs: np.ndarray):
""" Perform inference on a served RL model.
This will send an HTTP request to the Ray Serve endpoint of the served
RL policy model and return the result.
"""
action_dict = requests.post(endpoint_uri, json={"array": obs.tolist()}).json()
return action_dict步骤3:现在训练模型,使用Ray serve为其服务,评估服务的模型,最后关闭Ray serve。
# training in 20 workers using GPU result = train_rl_ppo_online(num_workers=20, use_gpu=True) # serving endpoint_uri = serve_rl_model(result.checkpoint) # evaluating rewards = evaluate_served_policy(endpoint_uri=endpoint_uri) # shutdown serve.shutdown()
Ray怀旧与潮流
Ray是作为UCB RISELab的一个研究项目启动的。RISELab是Spark诞生地AMPLab的继任者。
Ion Stoica教授是Spark和Ray的灵魂。他开始以Spark和Anyscale为核心产品创建Databricks。
我有幸在RISELab的早期阶段与研究员合作,见证了Ray的诞生。

Ray's project post at the conference 2017 (Photo courtesy by author)
以上是雷在2017年的项目帖子。我们可以看到,它非常简单,但对于人工智能应用程序来说功能强大。
雷是一艘恒星飞船,正在增殖。它是增长最快的开源之一,正如下面Github的星级数量所示。
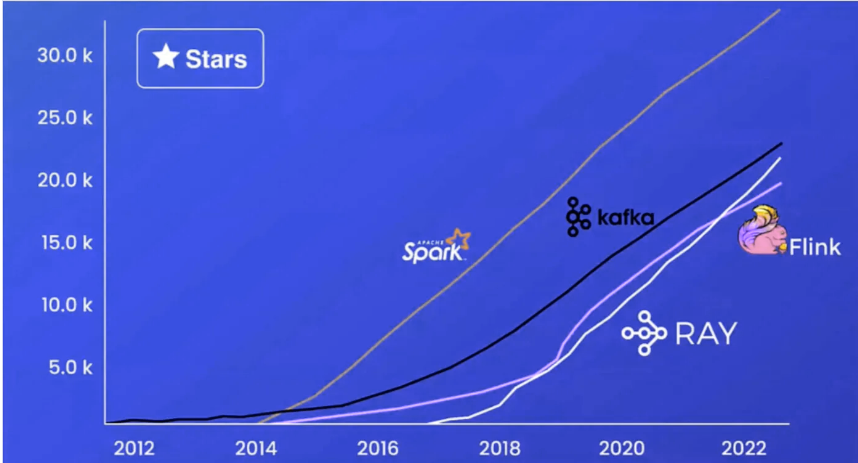
Ray正在人工智能工程领域崭露头角,是扩展LLM和RL的重要工具。Ray为未来巨大的人工智能机会做好了准备。
- 登录 发表评论