Alpaca是一个基于Meta的LLaMA系统的小型人工智能语言模型。出于安全和成本考虑,斯坦福大学的研究人员最近从互联网上删除了该演示。
大型语言模型包含数百亿或数百亿个参数,它们的访问通常仅限于有足够资源来训练和运行这些人工智能的公司。
快速增长的Meta决定与一些精选的研究人员分享其著名的LLaMA系统的代码。该公司希望找出语言模型产生有毒和虚假文本的原因。他们希望它能在研究人员不需要大规模硬件系统的情况下发挥作用。
于是,羊驼出生了。斯坦福大学的一组计算机科学家将LLaMA微调为一个名为Alpaca的新版本。这个新版本是一个开源的70亿参数模型。根据《新地图集》,它的建造成本不到600美元。
Alpaca已经调整了50000多个文本样本,使其信息更加准确
Alpaca的代码向公众发布,引起了几位开发人员的注意。他们成功地在树莓派电脑和Pixel 6智能手机上启动并运行了它。
斯坦福德的研究人员谈到了包括GPT-3.5、ChatGPT、Claude和Bing Chat在内的“指令遵循模型”是如何变得“越来越强大”的。该研究所的网站上写道:
“现在,许多用户定期与这些模型互动,甚至在工作中使用它们。然而,尽管它们得到了广泛部署,但遵循指令的模型仍然存在许多缺陷:它们会产生虚假信息,传播社会刻板印象,并产生有毒的语言。”
他们继续指出,如果问题得到正确解决,如果学术界参与其中,就可以取得最大的进展。
![]()
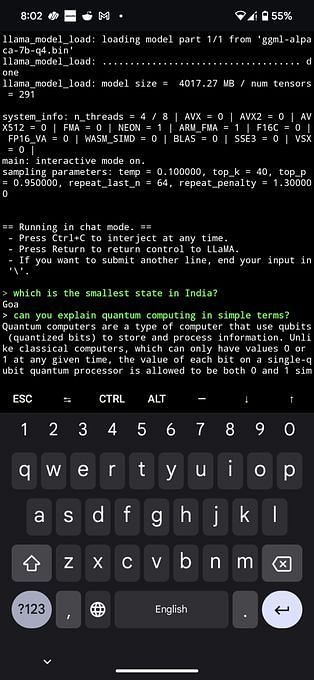
Alpaca 7B running on my Google Pixel 7 pro.
github.com/rupeshs/alpaca…
#alpaca #llama #pixel #llm #ai #chatgpt
研究人员谈到,由于缺乏开源模型,学术界对教学模型的研究变得困难,“比如OpenAI的text-davinci-003”
Alpaca已经用50000个文本样本进行了微调,这些样本指导模型并引导它遵循特定的说明。它有助于使其像text-davinci-003一样工作。该网页运行了人工智能模型的演示,并允许任何人和每个人与之互动。由于安全问题和在线托管成本的上升,基于LLaMA的模型很快就被拆除了。
斯坦福大学以人为中心的人工智能研究所的发言人在给《纪事报》的一份声明中表示:
“发布演示的最初目标是以一种可访问的方式传播我们的研究。我们认为我们基本上实现了这一目标,考虑到托管成本和内容过滤器的不足,我们决定取消演示。”
与其他语言模型类似,斯坦福变体也容易提供错误信息,通常被称为“幻觉”另一个常见的结果可能是冒犯性的文本。研究人员表示:
“幻觉似乎尤其是羊驼的常见故障模式,即使与text-davinci-003相比也是如此。”
一些人指出,当被问及坦桑尼亚首都时,该模型未能给出准确的答案,反而提供了虚假的技术信息。尽管该演示已从互联网上删除,但描述模型微调的数据集和代码仍可在GitHub上访问。研究人员也在进行谈判,以公布模型重量的细节。
该网站表示:
“Alpaca可能包含许多与底层语言模型和指令调优数据相关的其他限制。然而,我们相信该工件仍然对社区有用,因为它提供了一个相对轻量级的模型,可以作为研究重要缺陷的基础。”
人工智能,就像斯坦福大学的新变种一样,正在慢慢发展,并将比以往任何时候都更加强大和准确。
- 登录 发表评论